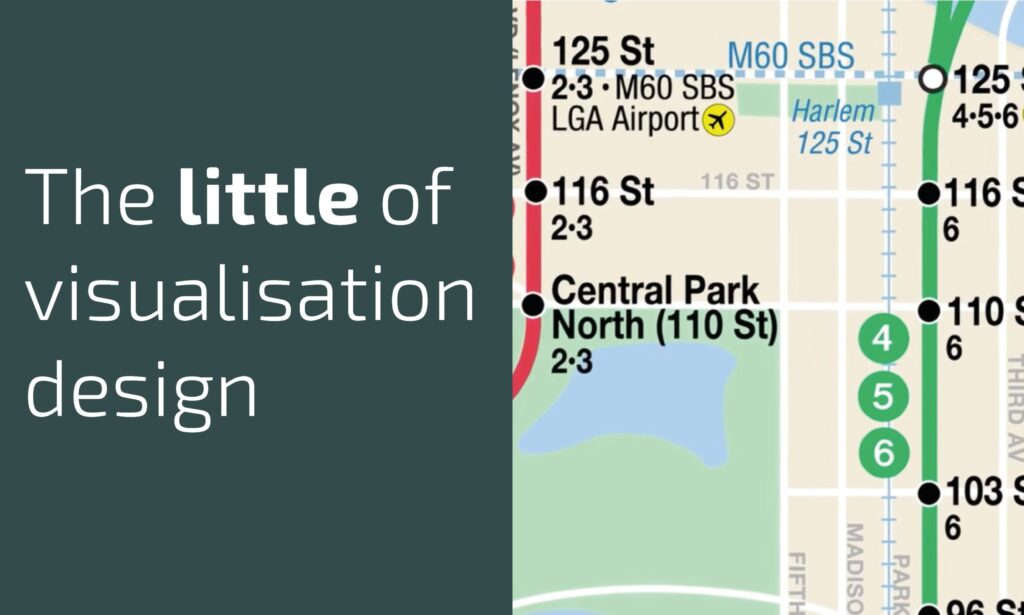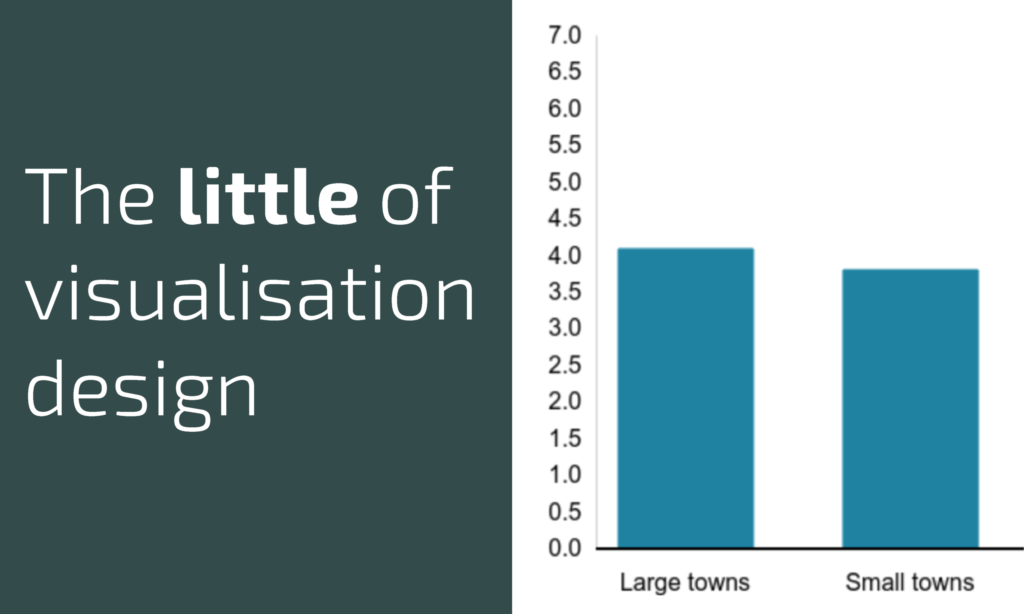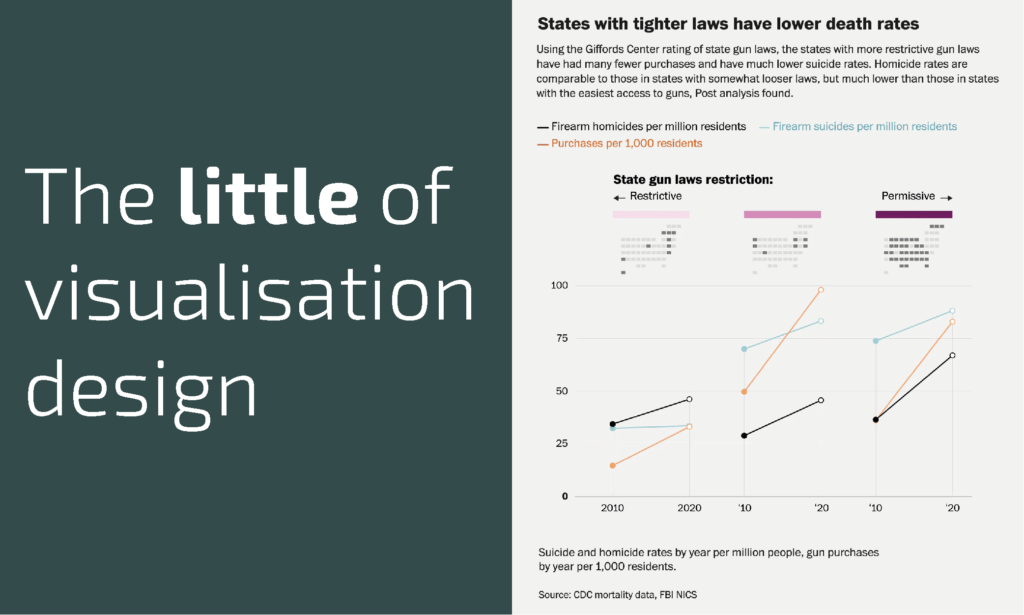
The little of visualisation design: Part 75
This is part of a series of posts about the ‘little of visualisation design’, respecting the small decisions that make a big difference towards the good and bad of this discipline.
The little of visualisation design: Part 75 Read More »