
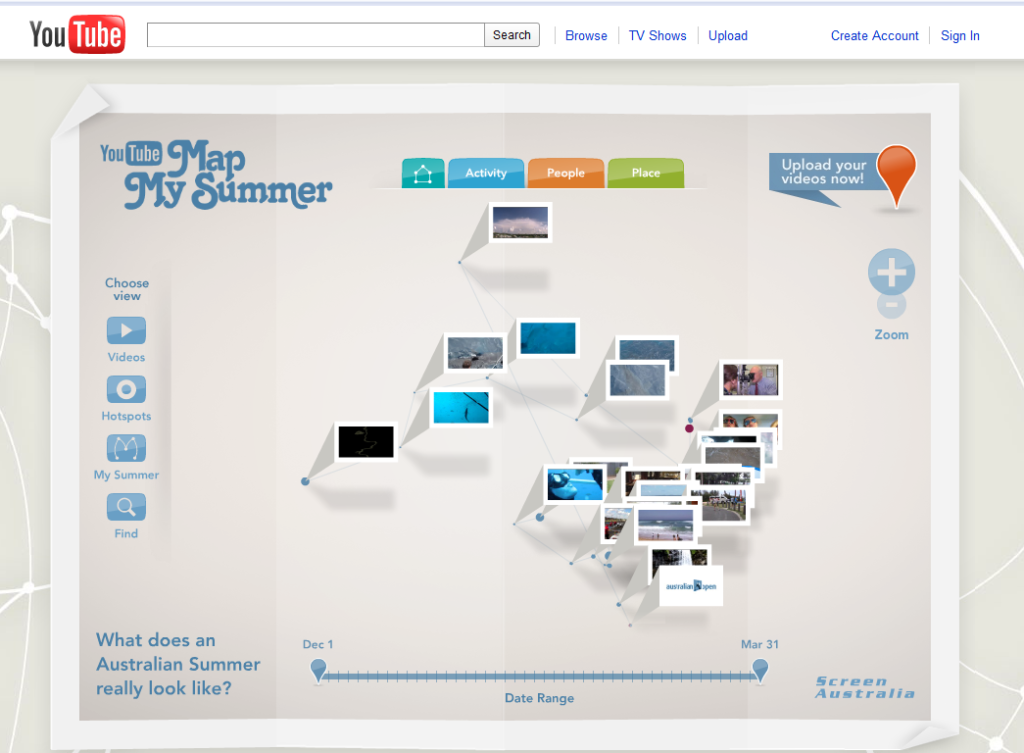
YouTube ‘Map My Summer’
Kristian Saliba, a digital art director for Three Drunk Monkeys creative agency (Sydney, Australia), has sent me details of an interesting project that has just been launched for YouTube titled ‘Map My Summer’.
YouTube ‘Map My Summer’ Read More »
