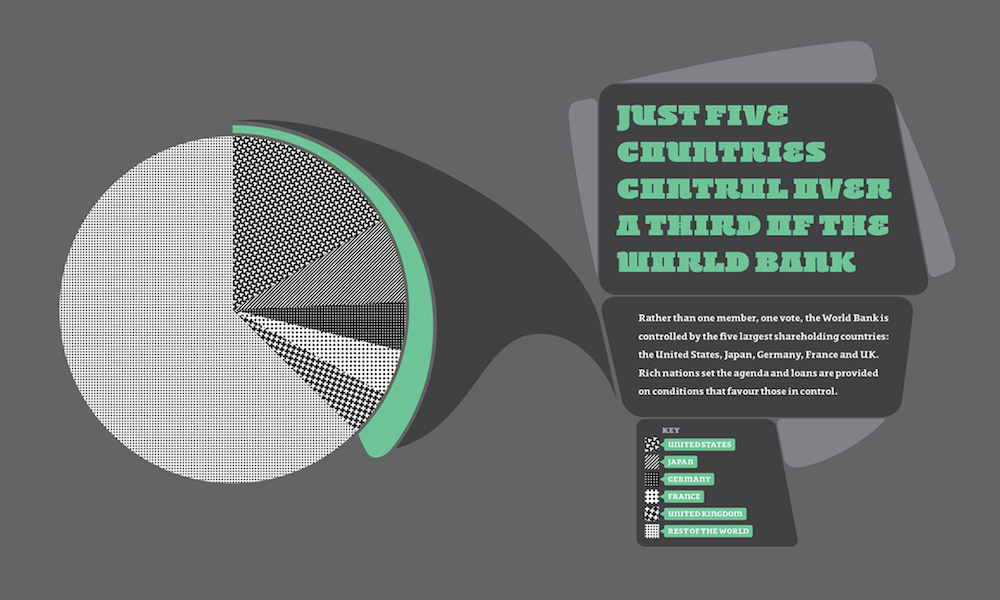
Visualisation Insights: #1 The visualisation designer
This post is the first in a series I am commencing called Visualisation Insights. The purpose of this series is to provide readers with unique insights into the field of visualisation from the different perspectives of those in the roles of designer, practitioner, academic, blogger, journalist and all sorts of other visual thinkers. My aim […]
Visualisation Insights: #1 The visualisation designer Read More »